
[This article is based on the MSc thesis ‘A Photometric Stereo Approach to Face Recognition‘ by Roger Woodman]
During recent times traditional personal identification methods have come under much scrutiny. This has mainly been due to increase fraud and attention surrounding terrorist activities. To meet the modern day needs of personal identification, a number of more robust methods have been researched. These methods, which aim to uniquely identify individuals using information about a person’s physical make up, are known as biometrics. An investigation into fourteen such biometric techniques has been conducted by Jain et al. (2004). Their research identifies face recognition as the only method with the potential of providing a non-intrusive system that could be publicly accepted in today’s society.
At present, two main factors restrain the widespread use of face recognition technology; these factors are system reliability and cost. The issue of system reliability has been addressed in many research projects, with recent advances in 3D imaging technology, reported by Zhao and Chellappa (2006), demonstrating increased levels of recognition accuracy compared to traditional 2D systems. The use of 3D data to produce 3D face models has been shown as an effective approach for handling a number of key difficulties in face recognition, which can degrade system performance. These issues are associated with illumination variance, head pose orientation and changes in facial expression. However, although 3D imaging systems have been shown to outperform equivalent 2D systems, more accurate equipment is often required at a greater expense.
1. Introduction
Personal identification has seen a number of advances in the last two decades. The term biometrics is used to encompass all methods which identify an individual based on physical attributes that can be both perceived and measured based on actions. Traditional biometric methods such as fingerprints and handwriting signatures have been shown as not reliable when operated on large data sets (Zhang et al., 2004).
In order to meet the demands of today’s security conscious society, a number of biometric methods have been proposed that in theory offer greater levels of reliability than traditional methods. A summary of what is required from a modern biometric system is given by Jain et al. (2004) “A practical biometric system should meet the specified recognition accuracy, speed, and resource requirements, be harmless to the users, be accepted by the intended population, and be sufficiently robust to various fraudulent methods and attacks to the system”. A number of biometric methods which meet these criteria have been investigated by Akarun et al. (2005). Their research has identified the following as viable personal identification methods:
- Iris
- Retina
- Hand
- 3D face
Of these biometric methods, 3D face has the potential to be the most cost effective and require the least cooperation from the individual being identified. “Although 2D and 3D face recognition are not as accurate as iris scans, their ease of use and lower costs make them a preferable choice for some scenarios.” (Akarun et al., 2005). The study by Zhao and Chellappa (2006) has reviewed the current research in biometric identification and the possibility of implementing each in real world situations. Their work has described the benefits of face recognition as being socially accepted, relatively low cost and has the potential to be integrated into current CCTV security networks, which exist in nearly all cities and secure locations.
The following section sections provide a review of the most established and up-to-date technologies in face recognition. An assessment of 2D and 3D recognition methods is given by means of compare and contrast. From these recognition methods a low cost solution for producing 3D face models is identified and investigated in more detail. Finally, techniques for evaluating different face recognition systems based on standardised tests are presented.
2. Face Recognition in Humans
Much of the generated interest surrounding automated face recognition is based on the ability of humans to effortlessly recognise other human faces, and the desire to recreate it using computer vision techniques (Hallinan et al., 1999). However, although it is apparent that humans in general are excellent at recognising familiar faces, many studies have shown that humans do not fare well when recognising unfamiliar faces from a single image. Research conducted by Sinha et al. (2006) shows that humans are able to recognise familiar faces of celebrities from blurred or partially occluded images. However, evidence is also presented, which shows that the ability to recognise faces is significantly reduced when presented with an unfamiliar face and asked to recall it from a collection of unfamiliar faces.
A number of studies have been conducted which compare human face recognition with the latest automated techniques. A study by Lund (2001) demonstrates that human’s process faces holistically. This means that the face is processed without analysing each feature individually. Further studies have shown that the individual measurements of facial features are not relied upon. An investigation by Zhao and Chellappa (2006) uses a single model of a face in order to align and resize the features of a number of images of different faces to a standard configuration. Their results show that there is little difference in the ability to recognise a face when altered in this way. Their investigation concludes that a human’s ability to recognise a face is heavily reliant on the face texture and shape of facial features and the shape of the face as a whole.
3. Face Recognition Using Computer Vision
Computer based face recognition is the process of recognising individual faces from a series of digital images, using computer driven algorithms to aid identification. Whether a face recognition system is semi-automated or fully automated, a similar process flow is used to identify a subject’s face from single or multiple images. This general process flow, as described by Zhao et al. (2003), involves; face detection, face quantifying and face recognition. These processes have been implemented in a variety of diverse ways, from using only the ‘raw’ 2D image data to 3D reconstructions of the entire face. However, these diverse methods all share a common aim, to quantify each individual face in order to prove its uniqueness (Hallinan et al., 1999). “To remember a face as an individual, and to distinguish it from other known and unknown faces, we must encode information that makes the face unique.” (Zhao and Chellappa, 2006).
For personal identification, face recognition can be used to authenticate an individual using one of three modes. These modes, as described by Lu (2003) are verification, identification and the watch list task. Verification is concerned with matching a query face with the enrolled image of a claimed individual’s identity using a one-to-one matching process. Identification uses a one-to-many scheme and involves matching a query face with an image in a face database to determine the individual’s identity. The watch list authentication task has been introduced recently and involves an open test where the query image may or may not represent an individual contained in the database. The query image is compared with all enrolled images of the database with a similarity score computed for each. If the similarity score is equal to or higher than a predefined alarm value then a match is made. This authentication task is designed for security situations, such as locating missing persons or for identifying prohibited individuals at border controls.
Many terms are often associated with how images are processed in face recognition. The term used to define the database of faces, used for recognition matching, is often called the enrolment database. This database is required in order to match a current face image, known as the query image, with a number of enrolled faces in the database (Li and Jain, 2004). The data contained in the enrolment database can be made up of 2D images and/or face information extracted from 3D models. The difference between a 2D image and a 3D model is that the 2D image generally provides no height information, thus the image can only be manipulated on the x and y axes. 3D models are made up of data defining the structure of an object; therefore the model can be rotated on the z axis, which allows for geometric data to be calculated, providing information about the actual distance on the face and the extent of protrusions for facial features (Bronstein et al., 2004a).
The remainder of this article will explore both automated and semi-automated face recognition approaches using computers. A review of face recognition systems by Zhao et al. (2003) shows that the majority of face recognition research use only greyscale images, due to the difficulties associated with colour images with respect to illumination conditions. As stated by Li and Jain (2004), the use of colour information is typically used only as a pre-processing step in order to separate a human face from the image background. Therefore, greyscale images will be assumed from here on unless otherwise stated.
4. Image Acquisition
Image acquisition in face recognition is the method of capturing a number of digital images for use in the recognition process. The techniques and equipment used to acquire images vary considerably depending on which face recognition approach is adopted. In general 2D techniques require much less equipment than 3D alternatives. The review of 2D systems by Zhao et al. (2003) states that for 2D systems all that is generally required is a single camera and a well-lit location. An exception, which has received little attention, is the use of thermal imaging cameras (Wolff et al., 2001). These cameras capture 2D images of the face surface temperature, with each pixel of the image representing a specific temperature.
It is necessary at this juncture to discuss the difference between a 3D model of the head and a 3D model of only the face. A 3D model of the head assumes height information for the entire head, thus the head model can be rotated 360°. A 3D model of the face assumes height information for only the facial features and the surrounding face surface. This is often known as a 2.5 Dimensional (2.5D) surface reconstruction (Vogiatzis et al., 2006). As face recognition is clearly only interested in the face and to avoid confusion, the term 3D will be used to address all models of the head whether present in 2.5D or 3D. The remainder of this article will discuss image acquisition for 3D systems.
Stereo imaging is a capture method that uses two cameras in order to simultaneously acquire two images of an object from slightly different viewpoints. Triangulation is applied to a number of points identified in both images in order to calculate the geometry of the presented object. Correspondence is a technique used to locate precise points of an object that can be readily identified in both images. An imaging process, which also relies on correspondence, uses orthogonal profile images of the face (Yin and Basu, 1997). The process can use either two cameras to capture the object in a single shot or a single camera held stationary and the object rotated between shots.
Photometric stereo is a modelling technique that use multiple images captured under different illumination directions to recover the surface gradient (Agrawal et al., 2005). The surface gradient defines the surface orientation for each point of the face, known as the surface normals. These surface normals can be integrated using a surface reconstruction algorithm to produce a model of the face surface. The technique is traditionally used for modelling static objects such as museum artifacts, however, recently evidence has been presented by Zhou et al. (2007), which demonstrates that acceptable face models can be produced using this technique. Photometric stereo will be covered in more depth in Section 6.
The final type of 3D imaging system is that which projects a light onto an object in order to measure how the object interacts with the light compared to a flat surface. Two such techniques are laser scanners and coded light. Laser-based techniques use a laser line to scan the entire surface; triangulation is then applied to each laser line to calculate the surface geometry. The coded light technique, projects a specially coded light pattern onto an object. Images are captured of the object and the light pattern, which are then processed to reveal depth information based on distortion of the project patterns.
In order to compare the 3D modelling techniques, which have been identified, for use in the area of face recognition, a number of key considerations need to be made. Zhao et al. (2003) defines a number of aspects which can be used to compare face recognition systems, these are:
- Quality of captured data
- Capture and recognition time
- Equipment cost
- Requirements of the user
- Intrusiveness
Of the capture methods identified here, laser scanning systems provide the most accurate results, and are often used to test the precision of results from systems using different capture methods. However, laser sensors are relatively expensive and much time is required in order to completely scan an object. “The acquisition of a single 3D head scan can take more than 30 seconds, a restricting factor for the deployment of laser-based systems.” (Akarun et al., 2005). Due to the time taken and visible laser projected onto the face, much cooperation is required from the user. The use of coded light is a relatively fast process. However, as with laser scanning a visible light pattern is projected onto the users face. Two methods, which require no projected light, are stereo and orthogonal imaging. These techniques use standard cameras, with stereo imaging requiring two cameras and orthogonal needing only one. Stereo imaging, as described by Li and Jain (2004), can produce accurate 3D models using little equipment. The main issue with these methods is the use of correspondence, which can be computationally expensive and produce errors in the results. ‘Often failure to identify a stereo correspondence point can result in a 3D surface, which contains ‘holes’ due to absent surface information’ (Zhao and Chellappa, 2006). A relatively fast 3D capture method, which does not require correspondence, is photometric stereo. This method requires a single camera and three lights. Further details of photometric stereo as a face recognition method will be presented in Section 6.
5. Prominent Face Recognition Methods
All computer aided face recognition systems use either 2D or 3D data in one form or another. The form of this data can differ between 2D and 3D systems, with 2D methods usually using colour or intensity values and 3D methods using geometric based values, range data or surface gradient data. According to Zhao et al. (2003) face recognition methods, using either 2D, 3D or both techniques together, can be organised into one of three groups:
- Feature-based methods
- Appearance-based methods
- Mixed methods
The first group, feature–based methods, segment the face into a number of components which can be analysed individually. This usually involves the identification of local features such as the eyes, nose and mouth. (Axnick and Ng, 2005). These local features can be analysed in a number of ways, using simple measurement techniques or more sophisticated template matching. Appearance-based methods use the whole face area as the input to the face recognition system. These methods typically operate on 2D images, using the raw image data to produce comparisons of other face images, from which a match can be made. The final mixed methods group combines both feature- and appearance-based methods to produce different results. It is argued that mixed methods should produce more reliable results, albeit with a greater computational cost. “Combination of feature- and appearance-based methods may obtain the best results.” Tangelder (2005).
The following sections describe a number of face recognition methods in more detail. Each method has relative merits and demerits and it is these properties that are used when choosing a method for any given face recognition task. ”Appropriate schemes should be chosen based on the specific requirements of a given task.” (Zhao et al., 2003).
5.1. Feature-based Methods
Early feature-based methods used a set of geometric feature points in order to measure and compare distances and angles of the face. Research by Starovoitov et al. (2002) uses 28 face points, manually selected on a number of 2D images, in order to describe the face. Their results show that this method is accurate in recognising faces, which are all of the same pose orientation. However, with varying pose the ability to recognise a face is significantly reduced. This process of locating geometric feature points has recently been applied to 3D face models. The evidence presented by Zhao et al. (2003), demonstrates that 3D feature location is more robust than 2D methods, allowing for large variation in subject pose and changes in facial expression.
Elastic bunch graph matching (EBGM) is a recently introduced technique, where a sparse grid is overlaid on the face and a number of grid points are adjusted to pre-defined feature locations. These grid points are used to calculate local feature vectors, which can then be used in face comparisons using a graph matching algorithm (Aguerrebere et al., 2007). A critical part of this method is accurate location of grid points, which can be difficult to achieve reliably. “The difficulty with this method is the requirement of accurate landmark localization.” (Bolme et al., 2003).
5.2. Appearance-Based Methods
The most prominent appearance-based method, which is also one of the earliest, is the Eigenface method introduced by Turk and Pentland. The Eigenface algorithm, as described by Turk and Pentland (1991), uses principal component analysis (PCA) to reduce the number of dimensions that make up the face to its principal components. These principal components are defined as the parts of the face image that exhibit the largest variations when compared to the training set. PCA is used to avoid direct correlation with all components of the face image, which as well as being computationally inefficient, also can result in unreliable data being processed. In contrast to feature-based methods, which rely on the location of facial points, the Eigenface method processes the face using a holistic approach, thus negating the requirement of any feature locating. For recognition the Eigenface method relies on the assumption that “the difference between two instances of the same face will be less than that between two different faces.” Hallinan et al. (1999).
Evidence of the Eigenface method, has shown it to produce accurate, reliable recognition results when presented with frontal face images under constant illumination conditions (Hallinan et al., 1999). However, the method is sensitive to variations in pose and illumination, which can have a significant effect on the reliability to match faces. To address these issues a recent method known as Fisherface has been conceived (Shakhnarovich and Moghaddam, 2004). The Fisherface method adds another dimension to the Eigenface technique, by using a larger training set containing multiple varying images of each subject face. The advantage of this is that more data is available to describe illumination conditions and pose orientation, which as a result makes the method more robust as more training images are presented. The method is inherently more complex than the Eigenface method and thus requires more computation time to both train the system and generate a face match.
5.3. Mixed Methods
Mixed methods combine aspects of both feature- and appearance based methods with the aim to produce more accurate and robust recognition results. The most widely used mixed method is Eigenfeatures (Torres et al., 1999). Eigenfeatures is a direct extension to Eigenface that uses feature locations in an aim to improve face matching. The process involves locating and separating individual face features, these face features are then processed individually using the Eigenface technique. Evidence is presented by (Torres et al., 1999), that this method provides more accurate recognition than the appearance-based method, Eigenface.
The following section provides a detailed explanation of photometric stereo and presents a review of the latest research conducted and technical developments made. The photometric stereo method can be used with mixed method face recognition, as both 2D images and 3D reconstructions can be produced.
6. Photometric Stereo
Photometric stereo is a technique used to recover the shape of an object from a number of images taken under different lighting conditions. The shape of the recovered object is defined by a gradient map, which is made up of an array of surface normals (Zhao and Chellappa, 2006). Each surface normal is a vector, which dictates the orientation for each of the facets of a surface. The diagram of Figure 3.1 illustrates a single surface normal. It can be seen from this diagram that the normal orientation is defined by an x, y and z component.
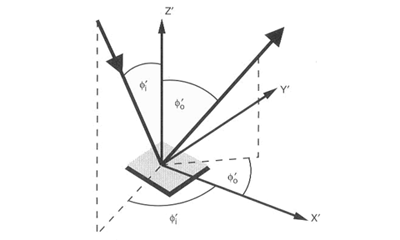 Figure 6.1 – Surface normal diagram (Zhao and Chellappa, 2006). Figure 6.1 – Surface normal diagram (Zhao and Chellappa, 2006). |
As photometric stereo uses computer images, each surface normal is attributed to the smallest unit of an image, which is known as a pixel. Therefore, the number of surface normals depends on the number of pixels contained in the image. To recover a surface normal at least three images are needed, each with a different light source direction (Kee et al., 2000). The requirement of three images under different light sources, adds minimal constraints on any photometric stereo system, these constraints are the use of three lights and the acquisition of three images. It has been shown by Vogiatzis et al. (2006) that it is possible to use multiple camera views to capture a larger surface of an object, however, the simplest and most accurate method is to use a constant camera view point. In addition to the gradient map, photometric stereo can also be used to produce an albedo image (Kee et al, 2000). This image is illumination invariant and describes the surface texture of the object without shape.
Although it has been shown that the minimum requirements of a photometric stereo system are three images taken under three different light sources, this in practice has associated with it two main issues, these issues are cast shadows and ambient light. The issue of cast shadows occur for objects where not all light sources reach the entire object surface, often caused by protrusions or overhangs of the object surface. This can result in missing data as surface normal calculations require at least three different intensity values to calculate a surface normal. To prevent missing data, a number of methods have been developed which capture more data of the object surface. The research by Raskar et al. (2004) and Chandraker et al. (2007) use four lights to capture four differently illuminated images of an object. The algorithm implemented by Rasker et al. (2004) uses all four images to calculate every surface normal of the object. An Alternative method, described by Chandraker et al. (2007) presents an algorithm where cast shadows are removed as a pre-processing step. Their approach is to select the three pixels of highest intensity from the four images and use these to calculate each surface normal. The second issue of using a minimal photometric stereo system is due to ambient light, which can cause incorrect calculations of the surface normals. This issue of ambient light, as highlighted by Bronstein et al. (2004a), can be ‘compensated for by subtraction of the darkness image’. The darkness image, which is referred to, is simply an image captured under ambient illumination alone.
The process of photometric stereo for 3D modelling is a well-documented technique. Much research has been shown that inanimate objects such as museum artifacts can be accurately modelled (Miyazaki et al., 2007) and (Vogiatzis et al., 2006). However, the research into photometric stereo as a face recognition technique is relatively under researched. Recent research into using photometric stereo for face recognition has been conducted by Zhou et al. (2007) and Bronstein et al. (2004a). Much of their research has shown that photometric stereo has the capability to produce accurate 3D models of human faces, which has the potential to be used in a face matching system.
A recent paper published by Miyazaki et al. (2007), describes a photometric stereo system which is able to model museum artifacts thought glass screens. An algorithm is presented, which removes the reflective effects of a glass surface, by selecting three of the five captured images, which contain no saturation due to direct reflection of light from the surface to the camera lens. This paper highlights the potential of using photometric stereo in face recognition. Although no mention of face recognition is made in the research by Miyazaki et al. (2007), it could be argued that this algorithm demonstrates a method that could be extended to the area of face recognition, in order to remove the effects of subjects wearing glasses or to capture face images through glass screens.
6.1. Surface Types
Photometric stereo can be used to model the majority of surfaces, however depending on the surface type different surface normal calculations must be used. Different surfaces can be divided into one of two types, Lambertian (after Johann Heinrich Lambert) and specular (Li and Jain, 2004). The diagram of Figure 3.2 illustrates the different properties of the two surfaces, when illuminated from a point source.
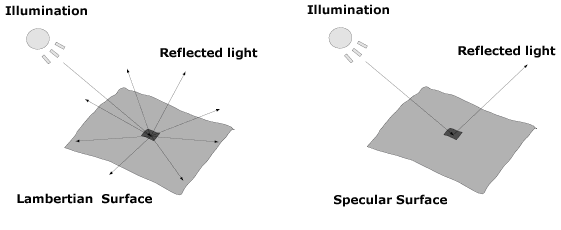 Figure 6.2 – Surface types: (a) Lambertian surface (b) Specular surface. Figure 6.2 – Surface types: (a) Lambertian surface (b) Specular surface. |
As illustrated in the diagram, Lambertian surfaces (Figure 3.2 (a)) reflect the incident light in all directions and appear equally bright when observed from any view point (Kee et al, 2000). Lambertian surfaces are found in materials such as cotton cloth, brick and matt paper and paints. Specular surfaces (Figure 3.2 (b)) reflect light at the same angle as the incident light, which results in different brightness being observed dependent on the view point. Specular surfaces are present on materials which reflect light, such as mirrors and polished metals.
For face recognition Lambertian surfaces are assumed, as the face skin is mostly a Lambertian surface (Kee et al, 2000). However, as Hallinan et al. (1999) states, the face as a whole can contain specular surfaces in the hair and eyes, which can cause specularities in the face data. These specularities are produced, when a specular surface is treated as Lambertian, producing an error value. The error values are often removed by averaging the surrounding values to reconstruct the surface (Zhao and Chellappa, 2006).
6.2. Surface Reconstruction
To produce 3D models from photometric stereo data it is necessary to integrate the gradient map to produce a height map. This height map, also known as a range map, defines the relative heights for each part of the surface, with the highest values representing those surfaces closest to the camera at time of capture (Lenglet, 2003).
Two integration techniques exist that can be used to reconstruct the gradient map, to produce a 3D model of the actual objects surface, these are local and global techniques. These techniques as described by Schlüns and Klette (1997) vary considerably in their performance and the reconstruction results. Local integration techniques start at a location within the gradient data, often the centre, and perform integration on neighbouring values, moving around the gradient map until a complete integration is achieved. Global integration techniques integrate the gradient map as a whole, using multiple scans in order to reconstruct the surface. Both local and global techniques have relative merits and demerits, which determine their use. Local techniques are relatively easy to implement and computationally fast, although dependent on data accuracy. Global techniques are computationally more expensive, however, are significantly more robust to noisy data (Schlüns and Klette, 1997). For photometric stereo, global integration is usually always used due to the noise present in computer images captured using this technique (Kovesi, 2005).
7. Recognition Issues
A number of issues exist in face recognition, which can impair the system’s ability to recognise faces. These issues can be grouped into two classes, internal factors and external factors (Bronstein et al., 2004a). Internal factors are associated with issues concerning the physical aspect of the face, such as facial expression, eyes open or closed and ageing. External factors are those that affect face recognition independent to the actual face; these are issues such as illumination conditions, head pose relative to the camera, facial occlusion and low quality images. As described by Li and Jain (2004) face recognition systems in general aim to handle these internal and external factors in one of three ways. The first approach is to use a standard capture system, where lighting and image quality is regulated, and to enforce rules, which the subject face must adhere to, such as central pose and a neutral facial expression. The second approach is to use a pre-processing step, which normalises the captured faces to the appropriate size, illumination level, pose and expression, based on an ideal face template. The final approach is to use an invariant representation of the face, which is insensitive to all changes in both internal and external factors. It is important to note that an invariant representation of the face has not yet been achieved and as stated by Bronstein et al. (2004a) “The ultimate goal of face recognition is to find some invariant representation of the face, which would be insensitive to all these changes”. The remainder of this section addresses the principal issues that presently exist in face recognition.
Illumination variations due to ambient light or unknown lighting directions can have the largest effect on the ability to recognise a face. “The changes induced by illumination are often larger than the differences between individuals” (Zhao and Chellappa, 2006). To manage variations in illumination a number of techniques have been developed, one of which has already been described for photometric stereo, where an image is taken under ambient lighting and subtracted from all other images. This technique can be used for any photometric systems. For 2D systems, the two main techniques used, are histogram equalisation and edge detection (Li and Jain, 2004). Histogram equalisation uses a graph of all image intensity values to determine information about the lighting conditions and offset their effects. Edge detection, also used for low quality images, is a technique used to highlight features within images based on steep transitions of intensity values. For face images this technique can be used to define the edge of the face and the majority of facial features.
The issue of head pose is a major concern for 2D face recognition developers, as slight variations in pose can affect the image results significantly. Methods which aim to handle pose variations typically use 3D models (Akarun et al. 2005). Face recognition systems can either use 3D models exclusively or as a pre-processing step to rotate the head to a central position from which 2D images can be produced. The later method is described by Bronstein et al. (2004a), where in their research a traditional Eigenface method is enhanced by fusing 2D and 3D data to produce a more robust method which is invariant to illumination and pose.
Variations in facial expression can affect the location of facial features and the overall shape of the face. This can affect both feature- and appearance-based face recognition methods. As with head pose variations, 3D models have been used in mathematical modelling to determine the facial expression and how the face has changed as a result (Zhao and Chellappa, 2006). These mathematical models can be adjusted to produce a neutral expression, which can be applied to 3D recognition or used to produce neutral 2D images.
The final prominent issue in face recognition is that of facial occlusion. Facial occlusion techniques are concerned with any articles that cover the face and subsequently affect recognition. These include items such as glasses, hats, jewellery, hair and cosmetics. The majority of techniques used to identify facial occlusions are based on 2D images (Zhao et al., 2003). The traditional method is to use template images of items, which could be present within an image, in order to search for and exclude their locations from the matching process. This process of excluding occluded areas, as described by Li and Jain (2004), is an often used technique for handling large facial occlusions, although it is shown that for smaller facial occlusions the face surface can sometimes be reconstructed using information from other parts of the face, however, this approach is purely subjective to the type and degree of occlusion. A final approach worth citing is the use of thermal imaging cameras to capture images of the face which highlight different areas of temperature (Wolff et al., 2001). This technique as examined by Zhao and Chellappa (2006) can reliably identify a number of facial occlusions such as glasses, hats and jewellery based on their temperature difference from the face surface. The identified items can subsequently be handled using one of the previously described methods.
8. Performance Measures
In order to compare face recognition systems and algorithms it is essential to use standard performance measures. The two most common performance measures are false accept rate (FAR) and false reject rate (FRR) (Li and Jain, 2004). The FAR measure denotes the number of unknown individuals identified as belonging to the enrolment database, whereas the FRR measure denotes the number of individuals, who appear in the database, falsely rejected. The importance of these performance measures is highlighted by Zhao and Chellappa (2006) where it is shown that the threshold used to determine if a face match has been found must be set to compromise between the number of query images falsely rejected and the number falsely accepted. As their research shows, the compromise between the two measures is often application specific, with more secure applications favouring much lower FAR’s with the associated effect of higher FRR’s.
As of 2000 the face recognition vendor test (FRVT) was established to meet the demands of researchers and companies who wanted to compare the abilities of their system with that of others (Li and Jain, 2004). The FRVT provides the means to compare different system performance using a number of standardised face databases. According to Zhao and Chellappa (2006), the databases created for the FRVT have become the benchmark for many face recognition research projects. The FRVT has been conducted in 2000, 2002 and again recently in 2006, the report by Phillips et al. (2007) presents the results of the 2006 FRVT. In their report they identify an improvement in the overall performance of the tested systems, which is described as being “due to advancement in algorithm design, sensors, and understanding of the importance of correcting for varying illumination across images.” (Phillips et al., 2007).
The bench mark used for the FRVT is a FRR of 0.01 (1 in 100) at a FAR of 0.001 (1 in 1000), with any system achieving these results, receiving an accreditation. As a comparison the ideal system would produce the results of 100% correct detection with zero false acceptances. The FRVT benchmark figure was first achieved in the 2006 test by two different systems, ‘the first by Neven Vision using high resolution still images and the second using a 3D imaging system produced by Viisage.’ (Phillips et al., 2007).
References
Zhao, W., Chellappa, R., (2006). Face processing: Advanced modeling and methods. Academic Press, Elsevier.
Li, S., Jain, A. K., (2005). Handbook of face recognition. Springer-Verlag, New York.
Hallinan, P. L., Gordon, G. G., Yuille, A. L., Giblin, P., Mumford, D., (1999). Two- and three-dimensional patterns of the face, A K Peters Limited, USA.
Braga, N. C., (2002). Robotics, mechatronics, and artificial intelligence. Newnes, USA.
Vogiatzis, G., Hernández, C., Cipolla, R., (2006). Reconstruction in the round using photometric normals and silhouettes. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2, pp 1847-1854.
Chandraker, M., Agarwal, S., Kriegman, D., (2007). ShadowCuts: Photometric stereo with shadows. Computer Vision and Pattern Recognition (CVPR ’07), pp 1-8.
Raskar, R., Tan, R., Feris, J., Turk, M., (2004). Non-photorealistic camera: Depth edge detection and stylized rendering using multi-flash imaging. ACM Transactions on Graphics (TOG), 23(3), pp 679-688.
Ng, A. K., Schlüns, K., (1998). Towards 3D model reconstruction from photometric stereo. IVCNZ 1998, pp 309-314
Bronstein, A. M., Bronstein, M. M., Gordon, E., Kimmel, R., (2004a). Fusion of 2D and 3D data in three-dimensional face recognition. International Conference on Image Processing (ICIP), 1, pp 87-90.
Bronstein, A. M., Bronstein, M. M., Kimmel, R., Spira, A., (2004b). Face recognition from facial surface metric. Proceedings of the European Conference on Computer Vision (ECCV), pp 225-237.
Miyazaki, D., Hara, K., Ikeuchi, K., (2007). Photometric stereo beyond glass: Active separation of transparent layer and five-light photometric stereo with M-estimator using laplace distribution for a virtual museum. Proceedings of the IEEE Workshop on Photometric Analysis For Computer Vision (PACV’07, in conjunction with ICCV 2007).
Zhao, W., Chellappa, R., Phillips, P. J., Rosenfeld, A., (2003). Face recognition: A literature survey. ACM Computer Survey, 35(4), pp 399-458.
Kee, S. C., Lee, K. M., Lee, S. U., (2000). Illumination invariant face recognition using photometric stereo. IEICE, 83(7), pp 1466-1474.
Gupta, H., Roy-Chowdhury, A. K., Chellappa, R., (2004). Contour-based 3D face modeling from a monocular video. Proceedings of the British Machine Vision Conference 2004, 1, pp 136-146.
Heseltine, T., Pears, N., Austin, J., (2002). Evaluation of image pre-processing techniques for Eigenface based face recognition. Proceedings of the Second International Conference on Image and Graphics, 4875, pp 677-685.
Kovesi, P., (2005). Shapelets correlated with surface normals produce surfaces. Tenth IEEE International Conference on Computer Vision, 2, pp 994-1001.
Lenglet, C., (2003). 3D surface reconstruction by shape from shading and photometric stereo methods. Proceedings of the ninth IEEE International Conference on Computer Vision (ICCV2003), pp 1-20.
Schlüns, K., Klette, R., (1997). Local and global integration of discrete vector fields. Advances in Theoretical Computer Vision, pp 149-158.
Tangelder, J., (2005). Survey of 2D face recognition methods for robust identification by smart devices. Technical report PNA-E0504, CWI, Amsterdam.
Axnick, K., Ng, A. K., (2005). Fast face recognition. Image and Vision Computing New Zealand (IVCNZ 2005).
Bolme, D. S., Beveridge, R., Teixeira, M., Draper, B. A., (2003). The CSU face identification evaluation system: Its purpose, features, and structure. Springer-Verlag, Berlin.
Aguerrebere, C., Capdehourat, G., Delbracio, M., Mateu, M., Fernandez, A., Lecumberry, F., (2007). Aguara: An improved face recognition algorithm through Gabor filter adaptation. Automatic Identification Advanced Technologies 2007 IEEE Workshop, pp 74-79.
Mian, A. S., Bennamoun, M., Owens, R., (2005). Region-based matching for robust 3D face recognition. British Machine Vision Conference (BMVC), 1, pp 199-208.
School of computer science and software engineering at the University of Western Australia, (2006). Frankot-Chellappa surface integration algorithm implemented in Matlab [online]. Available from: http://www.csse.uwa.edu.au/~pk/research/matlabfns [Accessed 20 July 2007].
Akarun, L., Gökberk, B., Salah, A. A., (2005). 3D Face Recognition for Biometric Applications. Proceedings of the European Signal Processing Conference.
Jain, K., Ross, A., Prabhakar, S., (2004). An introduction to biometric recognition. IEEE Transactions on Circuits and Systems for Video technology, 14, pp 4-20.
Wolff, L. B., Socolinsky, D. A., Eveland, C. K., (2001). Quantitative measurement of illumination invariance for face recognition using thermal infrared imagery. In Proceedings of the IEEE Workshop on Computer Vision Beyond the Visible Spectrum.
Agrawal, A., Chellappa, R., Raskar, R., (2005). An Algebraic Approach to Surface Reconstruction from Gradient Fields. IEEE International Conference on Computer Vision (ICCV), 1, pp 174-181.